CPU Core Overview
XiangShan-2 (NANHU) support single-core and dual-core configurations, where each core has its own private L1/L2 cache. L3 is shared by multiple cores.
NANHU communicates with the uncore through 3 AXI interfaces, including the memory port, the DMA port and the peripheral port. It also has clock, reset, and JTAG interfaces. Please refer to the integration guide for more detailed information.
NANHU targets 2GHz@14nm, and 2.4GHz~2.8GHz@7nm.
Typical Configurations
Below is the typical NANHU core configurations:
| Feature | NANHU (XiangShan-2) |
|---|---|
| Pipeline stage | 11 |
| Decoder width | 6 |
| Rename width | 6 |
| ROB | 256 |
| Physical register | 192(integer), 192(float) |
| Load Queue | 80 |
| Store Queue | 64 |
| L1 Instruction Cache | 64KB/128KB (4/8-way) |
| L1 Data Cache | 64KB/128KB(4/8 way) |
| L2 Cache | 512KB/1MB, 8-way, non inclusive |
| L3 Cache | 2MB~8MB, 8-way, non inclusive |
| Physical RF size | 192x64 bits, 14R8W |
| ECC Support | Y |
| Virtual Memory Support | Y |
| Physical memory protection | Y |
| Virtualization | N |
| Vector | N |
ISA Support
| Instruction Set | Description |
|---|---|
| I | Integer |
| M | Integer Multiplication and Division |
| A | Atomics |
| F | Single-Precision Floating-Point |
| D | Double-Precision Floating-Point |
| C | 16-bit Compressed Instructions |
| Zba | Bitmanip Extension - address generation |
| Zbb | Bitmanip Extension - basic bit manipulation |
| Zbc | Bitmanip Extension - carryless multiplication |
| Zbs | Bitmanip Extension - single-bit instructions |
| zbkb | Cryptography Extensions - Bitmanip instructions |
| Zbkc | Cryptography Extensions - Carry-less multiply instructions |
| zbkx | Cryptography Extensions - Crossbar permutation instructions |
| zknd | Cryptography Extensions - AES Decryption |
| zkne | Cryptography Extensions - AES Encryption |
| zknh | Cryptography Extensions - Hash Function Instructions |
| zksed | Cryptography Extensions - SM4 Block Cipher Instructions |
| zksh | Cryptography Extensions - SM3 Hash Function Instructions |
| svinval | Fine-Grained Address-Translation Cache Invalidation |
Instruction Latency
Most arithmetic instructions are single-cycle (Latency = 1).
Multi-cycle instructions are listed as follows.
| Instruction(s) / Operations | Latency | Descriptions |
|---|---|---|
LD |
4 (to ALU and LD), 5 (others) | Load operations (to use) |
MUL |
2 | Integer multiplier |
DIV |
4~20 | Integer divider (SRT16) |
FMA |
5 | Floating-point multiply-add instruction (cascade FMA) |
FADD, FMUL |
3 | Floating-point add/multiply operations |
FDIV/SQRT |
3~18 | Floating-point div/sqrt operations |
CLZ(W), CTZ(W), CPOP(W), XPERM(8/4), CLMUL(H/R) |
2 | Complex bit manipulation |
AES64*, SHA256*, SHA512*, SM3*, SM4* |
2 | Complex scalar crypto operations |
Priviledge Mode
NANHU supports three levels of privilege mode: machine (M), supervisor (S), and user (U).
Microarchitecture
Please refer to Section CPU Core for more details.
Cache Controller
There is a cache controller connected to L3 Cache, which used to perform Cache Maintenance Operation (CMO). Programmers ought to use MMIO based memory access to trigger operation required.
The following is a register table of the L3 cache controller.
| Address | Width | Attr. | Description |
|---|---|---|---|
| 0x3900_0100 | 8B | RW | Tag register of the interest cache block |
| 0x3900_0108 | 8B | RW | Set register of the interest cache block |
| 0x3900_0110 | 8B | RW | Way register of the interest cache block (deprecated) |
| 0x3900_0118 - 0x3900_0150 | 64B in total | RW | Data register of the interest cache block (deprecated) |
| 0x3900_0180 | 8B | RO | Flag register indicates ready for receiving next commandValue 1 indicates ready, 0 indicates not ready |
| 0x3900_0200 | 8B | WO | Command register for cache operationSupported commands are: Command Number 16 ( CMD_CMO_INV)Command Number 17 ( CMD_CMO_CLEAN)Command Number 18 ( CMD_CMO_FLUSH) |
A standard Cache operation follows the following process:
-
Inquire the
Flagregister, which indicates ready for receiving requests when valid -
Set
Tagregister to the tag of the interest cache block -
Set
Setregister to the set of the interest cache block -
Write command number to
Commandregister
Afterwards, the command is desired to be done.
There are three commands available.
-
Command Number 16 (
CMD_CMO_INV): Invalidate the cache block from cache hierarchy (Note that this operation may break cache coherence). -
Command Number 17 (
CMD_CMO_CLEAN): make cache block data in memory up-to-date. In other words, write back a block to memory if it is dirty in cache hierarchy. In current implementation, this command behaves just likeCMD_CMO_FLUSH. -
Command Number 18 (
CMD_CMO_FLUSH): flush the cache block to memory. In other words, write back a block to memory and invalidate the block.
Hardware Performance Monitor (HPM)
Architecture
Using distributed HPM (hardware performance monitor). There is an independent HPM in each block, and the HPM can also contain mirrored values of some other CSRs (the mirrored registers can only be modified by instructions). Each HPM contains multiple performance counter registers for counting internal events. For the number of performance counters, refer to the number of performance events to be counted simultaneously for different blocks. Each performance counter contains the following registers:
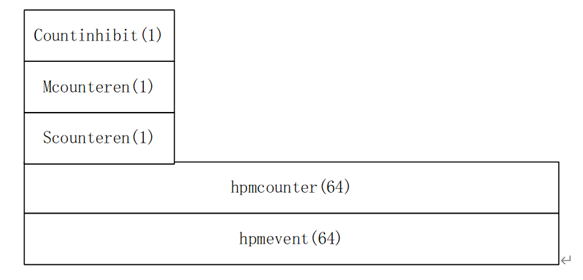
Each hpmevent is 64 bits. In order to count the events combined by multiple events, the event fields are now split according to the function. The split is as follows.

Mode represents that the corresponding performance counter is to be counted in a specific mode. Onehot encoding is adopted, and the encoding table is as follows.
Table.1 Performance counter register
| Privilege Mode | Mode Coding | Event Coding |
|---|---|---|
| M | Mode[4] | Mode[63] |
| H | Mode[3] | Mode[62] |
| S | Mode[2] | Mode[61] |
| U | Mode[1] | Mode[60] |
| D | Mode[0] | Mode[59] |
Event indicates the performance event code to be counted, with a total of four event fields. Where event equals 0 means no event, event equals all 1, means cycle. The Event coding table needs to be supplemented later. When an illegal value is written, the write operation is ignored. Events are classified by block. Between two consecutive blocks, there can be overlapping parts. The overlap is used for performance counter statistics between blocks. The optype encoding table is as follows:
Table.2 Mode and Event Coding
| Optype | Mode Coding |
|---|---|
'b00000 |
Or |
'b00001 |
And |
'b00002 |
Xor |
'b00003 |
Add |
'b00004 |
Sub |
Table.3 Optype encoding table
| Name | Address | Width | Description |
|---|---|---|---|
| Mhpmcounter31-3 | 0xB03-0xB1F | 64 | 64-bit accumulator. Counts based on selected events. The maximum data accumulated at one time is not fixed. |
| Mhpmevent31-3 | 0x323-0x33F | 64 | Event selection, decides under what conditions to count. |
| Mcountinhibit | 0x320 | 32 | Each bit controls whether the performance counter can be accumulated. 1: The accumulator does not change; 0: Accumulator counts up according to performance. |
| Mcounteren | 0x306 | 32 | Controls whether the S state has permission to access the corresponding performance counter. 0: S-state program access to hpmcounter register will report an illegal instruction; 1: S-state programs can access hpmcounter. |
| Scounteren | 0x106 | 32 | According to the value of Mcounteren, it is used to control whether the U state has permission to access the corresponding performance counter. Mcounteren[i] & Scounteren[i] == 0: An illegal instruction exception will be reported when a U-state program accesses the hpmcounter[i] register; Mcounteren[i] & Scounteren[i] == 1: U-state programs can access hpmcounter[i]. |
| pmcounter31-3 | 0xC03-0xC1F | 64 | Mirror for Mhpmcounter31-3. |
Linux Support
We have provided an example implementation with riscv-pk and riscv-linux. If you have any issues regarding the SBI and Linux syscall implementations, please refer to the source code.
We have also provided an example of the user program to configure and read the performance counters.
hpmdriver.h includes macro definition, configuring, reading or clearing methods of performance counters, and wraps syscall; set_hpm.c and read_hpm.c are for configuring and reading HPM, respectively.
List of the Performance Counters
For the update-to-date implemented performance counters, please see the Chisel elaboration logs when generating the verilog.
The table below presents an example of events. Please note that hardware performance monitors are highly configurable, so the information provided may NOT perfectly align with real-world cases. If you require additional counters, we recommend directly modifying the Chisel code.
Please refer to the source code for the detailed update conditions of these counters. We want to emphasize that we cannot guarantee the accuracy of the existing performance counters. It is important to understand that utilizing these counters is done at your own risk, and we advise taking necessary precautions.
Table.4 Example of the Performance Event Table
| BlockName | Event |
|---|---|
| Frontend | FrontendBubble |
| IFU | frontendFlush |
| IFU | to_ibuffer_package_num |
| IFU | crossline |
| IFU | lastInLine |
| Ibuffer | ibuffer_flush |
| Ibuffer | ibuffer_hungry |
| IFU | to_ibuffer_cache_miss_num |
| Icache | icache_miss_req |
| icache | Icache_miss_penalty |
| FTQ | bpu_to_ftq_stall |
| FTQ | mispredictRedirect |
| FTQ | replayRedirect |
| FTQ | predecodeRedirect |
| FTQ | to_ifu_bubble |
| FTQ | to_ifu_stall |
| FTQ | from_bpu_real_bubble |
| FTQ | BpInstr |
| FTQ | BpRight |
| FTQ | BpWrong |
| FTQ | BpBInstr |
| FTQ | BpBRight |
| FTQ | BpBWrong |
| FTQ | BpJRight |
| FTQ | BpJWrong |
| FTQ | BpIRight |
| FTQ | BpIWrong |
| FTQ | BpCRight |
| FTQ | BpCWrong |
| FTQ | BpRRight |
| FTQ | BpRWrong |
| FTQ | ftb_false_hit |
| FTQ | ftb_hit" |
| TAGE | tage_table_hits |
| TAGE | commit_use_altpred_b0 |
| TAGE | commit_use_altpred_b1 |
| SC | sc_update_on_mispred |
| SC | sc_update_on_unconf |
| BPU | s2_redirect |
| uBTB | ftb_commit_hits |
| uBTB | ftb_commit_misses |
| uBTB | ubtb_commit_hits |
| uBTB | ubtb_commit_misses |
| IBUFFER | ibuffer_empty |
| IBUFFER | ibuffer_12_valid |
| IBUFFER | ibuffer_24_valid |
| IBUFFER | ibuffer_36_valid |
| IBUFFER | ibuffer_full |
| FusionDecoder | fused_instr |
| DecodeStage | waitInstr |
| DecodeStage | stall_cycle |
| DecodeStage | utilization |
| DecodeStage | storeset_ssit_hit |
| DecodeStage | ssit_update_lxsx |
| DecodeStage | ssit_update_lysx |
| DecodeStage | ssit_update_lxsy |
| DecodeStage | ssit_update_lysy |
| Rename | in |
| Rename | waitInstr |
| Rename | stall_cycle_dispatch |
| Rename | stall_cycle_fp |
| Rename | stall_cycle_int |
| Rename | stall_cycle_walk |
| BusyTable | busy_count |
| StdFreeList | utilization |
| StdFreeList | allocation_blocked |
| StdFreeList | can_alloc_wrong |
| Dispatch1 | storeset_load_wait |
| Dispatch1 | storeset_store_wait |
| Dispatch1 | in |
| Dispatch1 | empty |
| Dispatch1 | utilization |
| Dispatch1 | waitInstr |
| Dispatch1 | stall_cycle_lsq |
| Dispatch1 | stall_cycle_roq |
| Dispatch1 | stall_cycle_int_dq |
| Dispatch1 | stall_cycle_fp_dq |
| Dispatch1 | stall_cycle_ls_dq |
| DispatchQueue_int | in |
| DispatchQueue_int | out |
| DispatchQueue_int | out_try |
| DispatchQueue_int | fake_block |
| DispatchQueue_int | queue_size_4 |
| DispatchQueue_int | queue_size_8 |
| DispatchQueue_int | queue_size_12 |
| DispatchQueue_int | queue_size_16 |
| DispatchQueue_int | queue_size_full |
| DispatchQueue_fp | in |
| DispatchQueue_fp | out |
| DispatchQueue_fp | out_try |
| DispatchQueue_fp | fake_block |
| DispatchQueue_fp | queue_size_4 |
| DispatchQueue_fp | queue_size_8 |
| DispatchQueue_fp | queue_size_12 |
| DispatchQueue_fp | queue_size_16 |
| DispatchQueue_fp | queue_size_full |
| DispatchQueue_lsu | in |
| DispatchQueue_lsu | out |
| DispatchQueue_lsu | out_try |
| DispatchQueue_lsu | fake_block |
| DispatchQueue_lsu | queue_size_4 |
| DispatchQueue_lsu | queue_size_8 |
| DispatchQueue_lsu | queue_size_12 |
| DispatchQueue_lsu | queue_size_16 |
| DispatchQueue_lsu | queue_size_full |
| Dispatch2Ls | in |
| Dispatch2Ls | out |
| Dispatch2Ls | out_load0 |
| Dispatch2Ls | out_load1 |
| Dispatch2Ls | out_store0 |
| Dispatch2Ls | out_store1 |
| Dispatch2Ls | blocked |
| roq | interrupt_num |
| roq | exception_num |
| roq | flush_pipe_num |
| roq | replay_inst_num |
| roq | clock_cycle |
| roq | commitUop |
| roq | commitInstr |
| roq | commitInstrMove |
| roq | commitInstrMoveElim |
| roq | commitInstrFused |
| roq | commitInstrLoad |
| roq | commitInstrLoadWait |
| roq | commitInstrStore |
| roq | writeback |
| roq | walkInstr |
| roq | walkCycle |
| roq | queue_1/4 |
| roq | queue_1/2 |
| roq | queue_3/4 |
| roq | queue_full |
| rs | alu0_rs_full |
| rs | alu1_rs_full |
| rs | alu2_rs_full |
| rs | alu3_rs_full |
| rs | load0_rs_full |
| rs | load1_rs_full |
| rs | store0_rs_full |
| rs | store1_rs_full |
| rs | mdu_rs_full |
| rs | misc_rs_full |
| rs | fmac0_rs_full |
| rs | fmac1_rs_full |
| rs | fmac2_rs_full |
| rs | fmac3_rs_full |
| rs | fmisc0_rs_full |
| rs | fmac1_rs_full |
| PageTableWalker | fsm_count |
| TLB | first_access |
| TLB | access |
| TLB | first_miss |
| TLB | miss |
| TLBStorage | access |
| TLBStorage | hit |
| PageTableCache | access |
| PageTableCache | l1_hit |
| PageTableCache | l2_hit |
| PageTableCache | l3_hit |
| PageTableCache | sp_hit |
| PageTableCache | pte_hit |
| L2TLBMissQueue | mq_in_count |
| L2TLBMissQueue | mem_count |
| L2TLBMissQueue | mem_cycle |
| MemBlock | load_rs_deq_count |
| MemBlock | store_rs_deq_count |
| StoreQueue | vaddr_match_failed |
| StoreQueue | vaddr_match_really_failed |
| StoreQueue | queue_1/4 |
| StoreQueue | queue_1/2 |
| StoreQueue | queue_3/4 |
| StoreQueue | queue_full |
| LoadQueue | rollback |
| LoadQueue | queue_1/4 |
| LoadQueue | queue_1/2 |
| LoadQueue | queue_3/4 |
| LoadQueue | queue_full |
| LoadQueue | refill |
| LoadQueue | utilization_miss |
| LoadUnit | in |
| LoadUnit | tlb_miss |
| LoadUnit | in |
| LoadUnit | dcache_miss |
| LoadPipe | load_req |
| LoadPipe | load_hit_way |
| LoadPipe | load_replay_for_data_nack |
| LoadPipe | load_replay_for_no_mshr |
| LoadPipe | load_hit |
| LoadPipe | load_miss |
| NewSbuffer | do_uarch_drain |
| NewSbuffer | sbuffer_req_valid |
| NewSbuffer | sbuffer_req_fire |
| NewSbuffer | sbuffer_merge |
| NewSbuffer | dcache_req_valid |
| NewSbuffer | dcache_req_fire |
| NewSbuffer | StoreQueueSize |
| WritebackQueue | wb_req |
| WritebackQueue | wb_release |
| WritebackQueue | wb_probe_resp |
| MainPipe | pipe_req |
| MainPipe | pipe_total_penalty |
| dcache | MissQueue |
| dcache | MissQueue |
| dcache | MissQueue |
| dcache | MissQueue |
| dcache | MissQueue |
| dcache | Probe |
| dcache | Probe |
Created: August 24, 2023